Rancher 开启监控后的,阈值告警配置说明 (三)
文章目录
环境说明
此文档为 rancher
monitor使用系列的第三篇,主要介绍与dingtalk关联配置告警通知、prometheus 告警阈值的配置使用
配置安装 dingtalk webhook
安装 kustomize
|
|
使用 kustomize 部署 deployment
-
clone 代码
1 2 3 4 5yum install -y git # 安装 git git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git cd prometheus-webhook-dingtalk/contrib/k8s/ -
创建 dingtalk 自定义机器人
安全设置这里我们选择
加签处理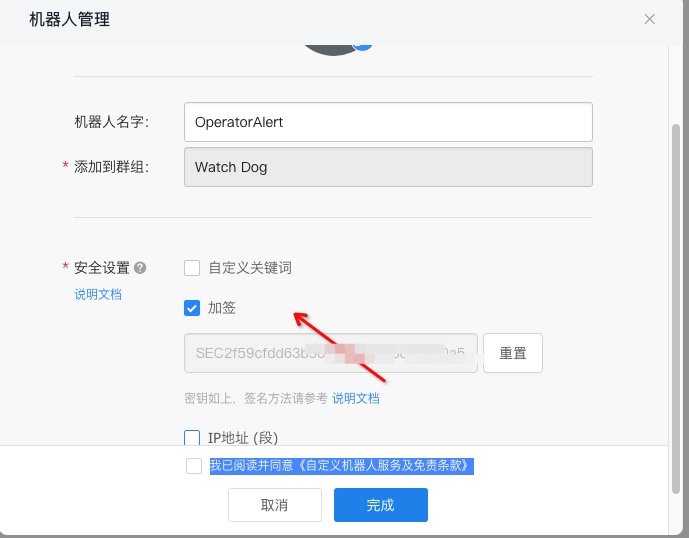
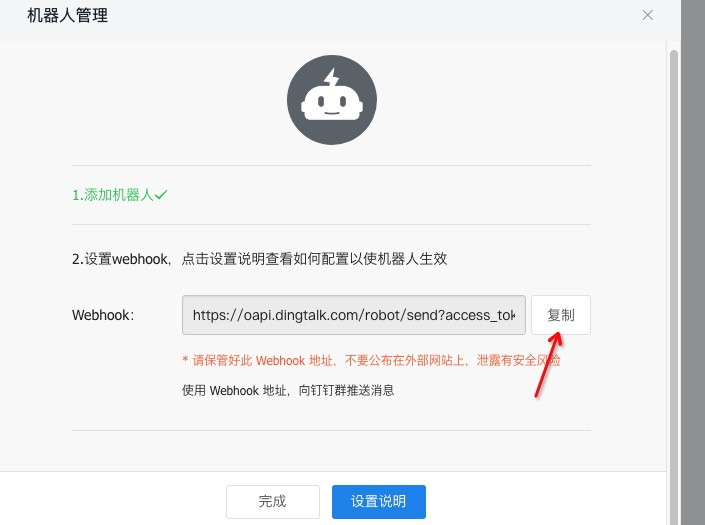
复制机器人
webhook信息填入至配置文件中
|
|
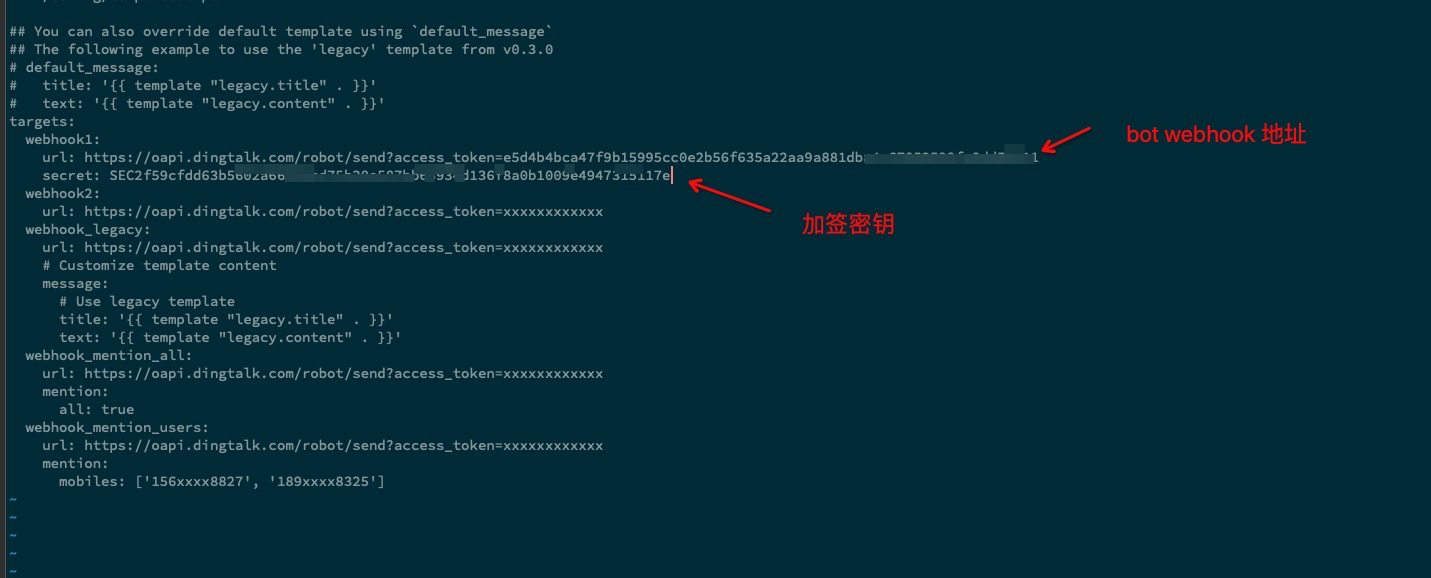
-
部署
yaml配置文件1 2 3 4 5 6sed -i "s#monitoring#prometheus#g" kustomization.yaml # 修改 配置文件中指定部署的 命名空间 kustomize build|kubectl apply -f - # 执行部署 configmap/alertmanager-webhook-dingtalk-f5hkbg7g25 created service/alertmanager-webhook-dingtalk created deployment.apps/alertmanager-webhook-dingtalk created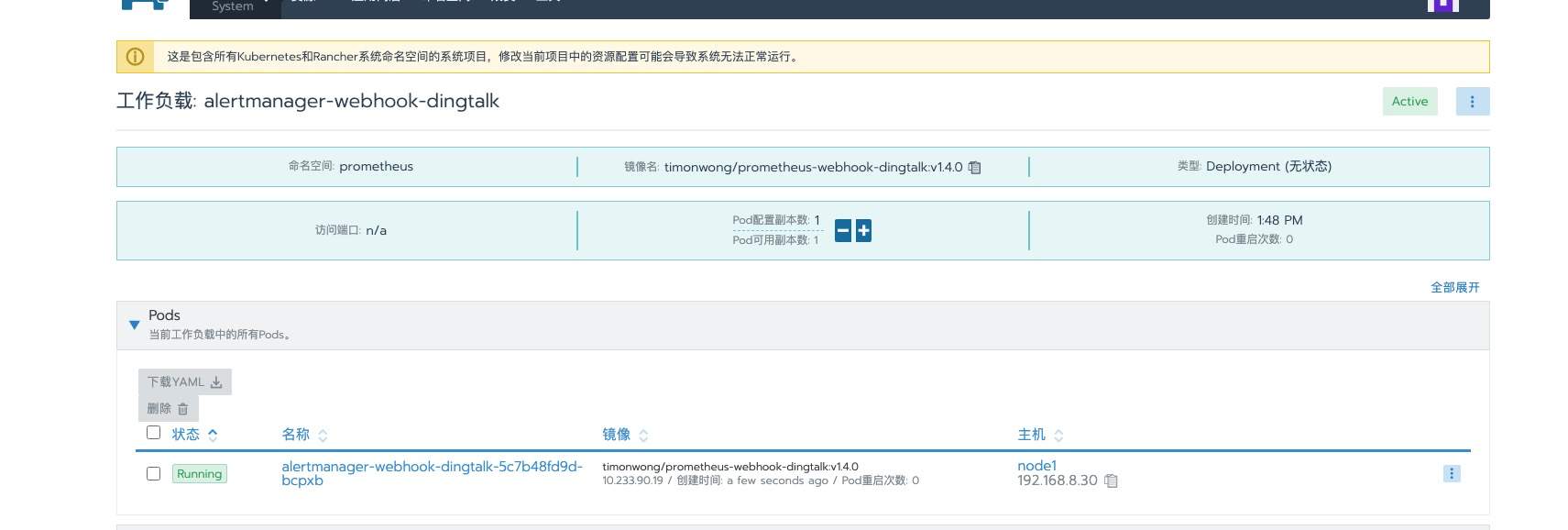
-
测试是否可以正常发送通知
1 2 3 4 5kubectl get po alertmanager-webhook-dingtalk-5c7b48fd9d-bcpxb -n prometheus -o wide # 获取 pod ip curl 'http://10.233.90.19:8060/dingtalk/webhook1/send' \ -H 'Content-Type: application/json' \ -d '{"Status": "testing"}'

正常将信息发送至 机器人,而且还做了转
大写处理,这是因为我们默认使用的template里面做了操作导致。
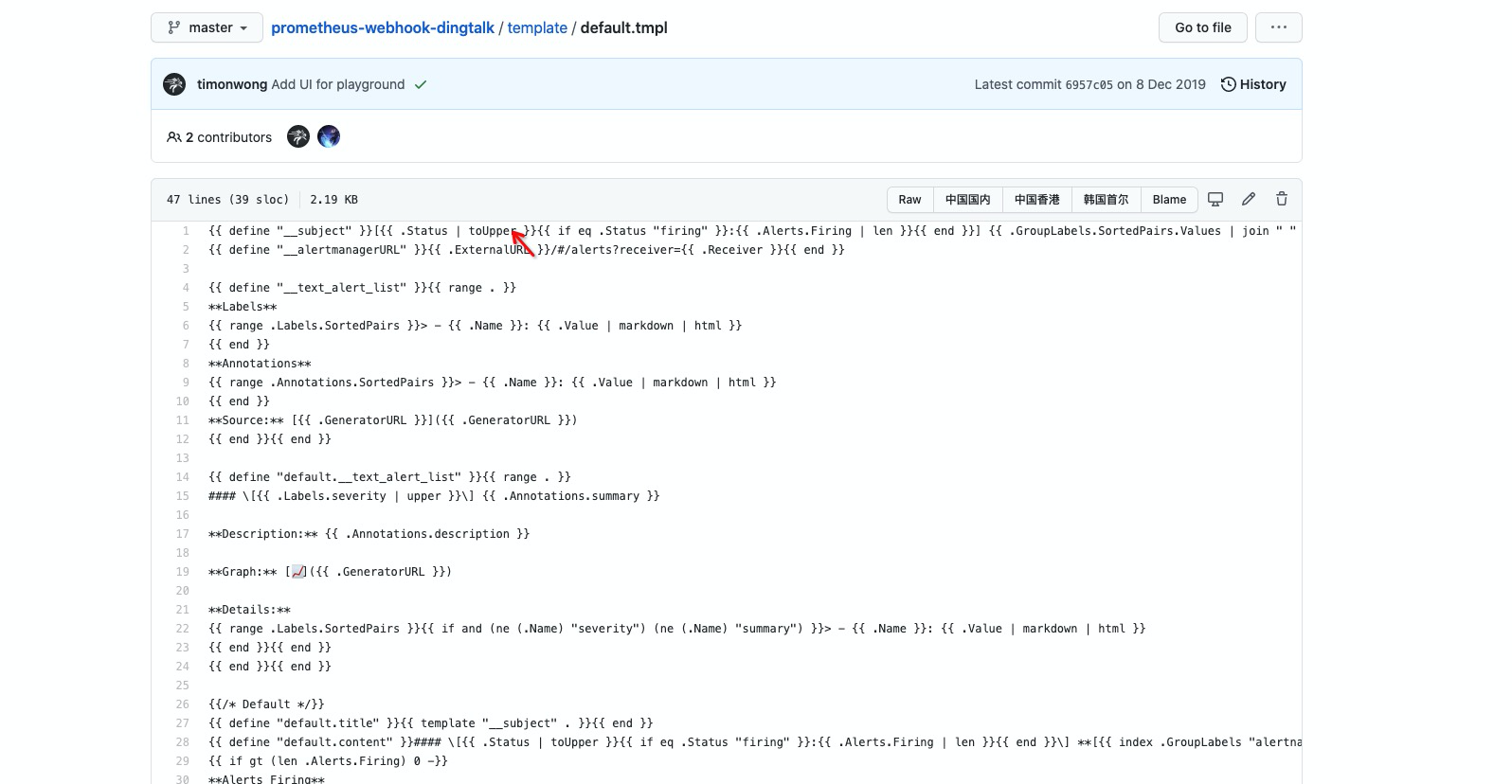
Rancher alertmanage 配置
alertmanage 的安装非常简单 只需要在 rancher 对应的 dashboard 中设置开启通知, 就会自动帮我去创建相应的
alertmanageclustert。
关联前面部署的 dingtalk webhook
点击通知
添加通知
选择添加
webhook类型通知,名称随意设置,webhook 的地址,我们这里配置使用 k8s内部域名,测试时无法解析此域名属于正常现象,因为所部署的rancher并不在当前k8s中,只要保证后面的alertmanage可以正常访问即可,确认后点击添加。
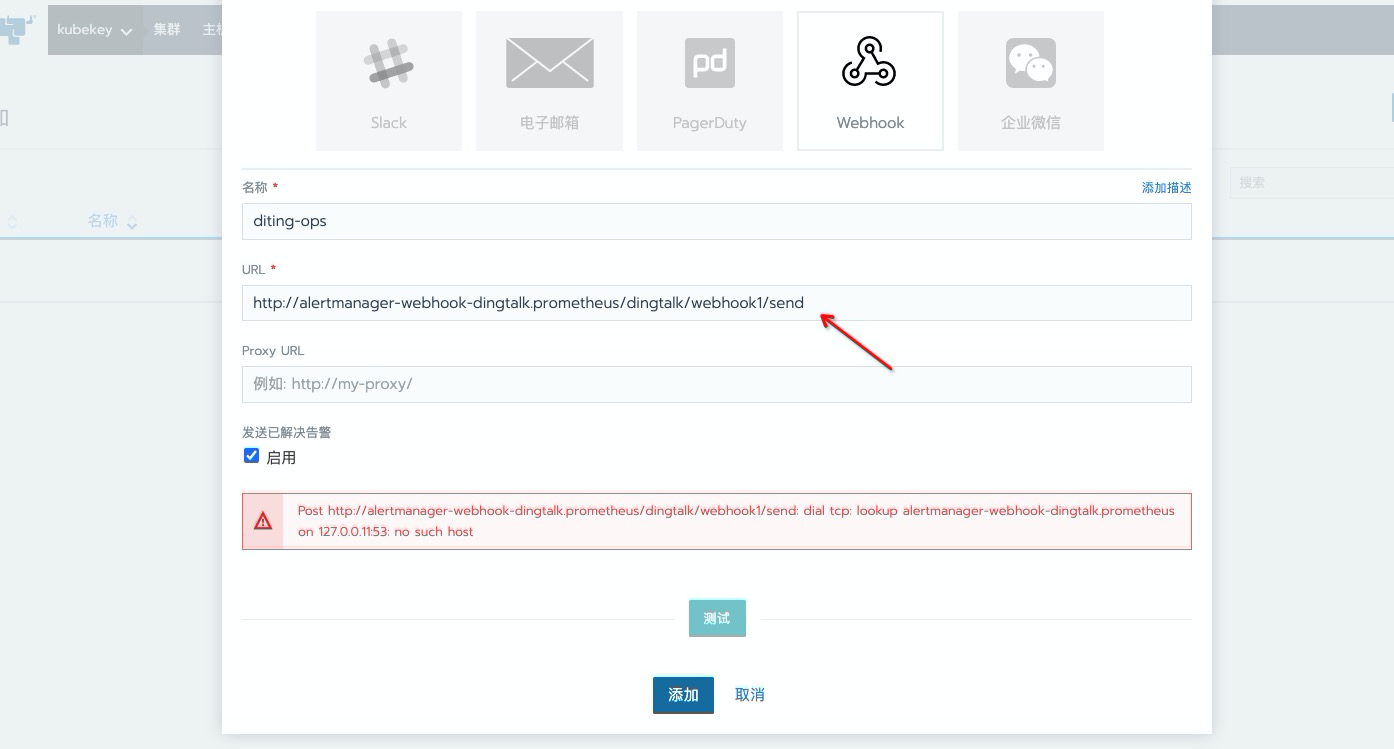
手动测试,告警是否有生效
点击告警
选择一组告警组 关联刚才添加的通知

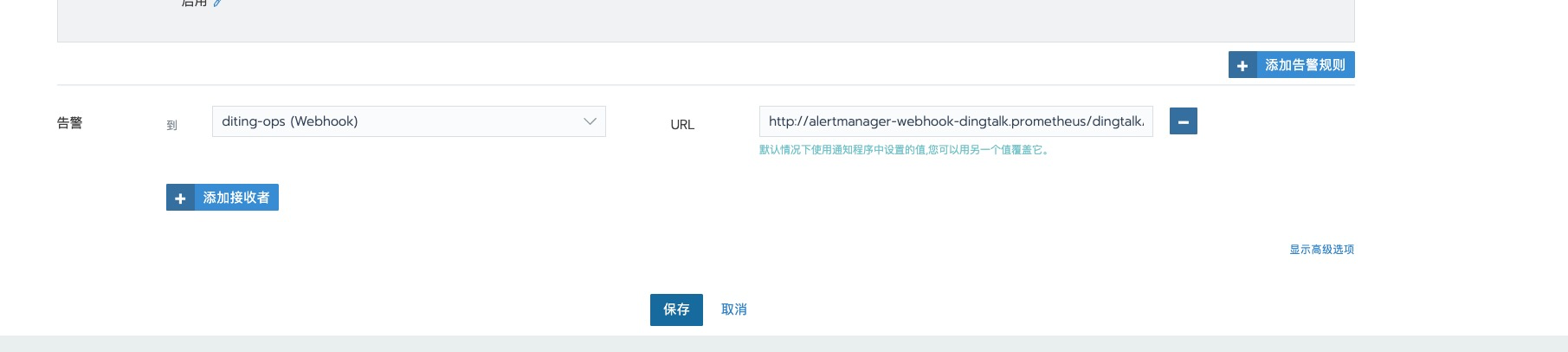
拉到最下面 设置为我们上面添加的 告警
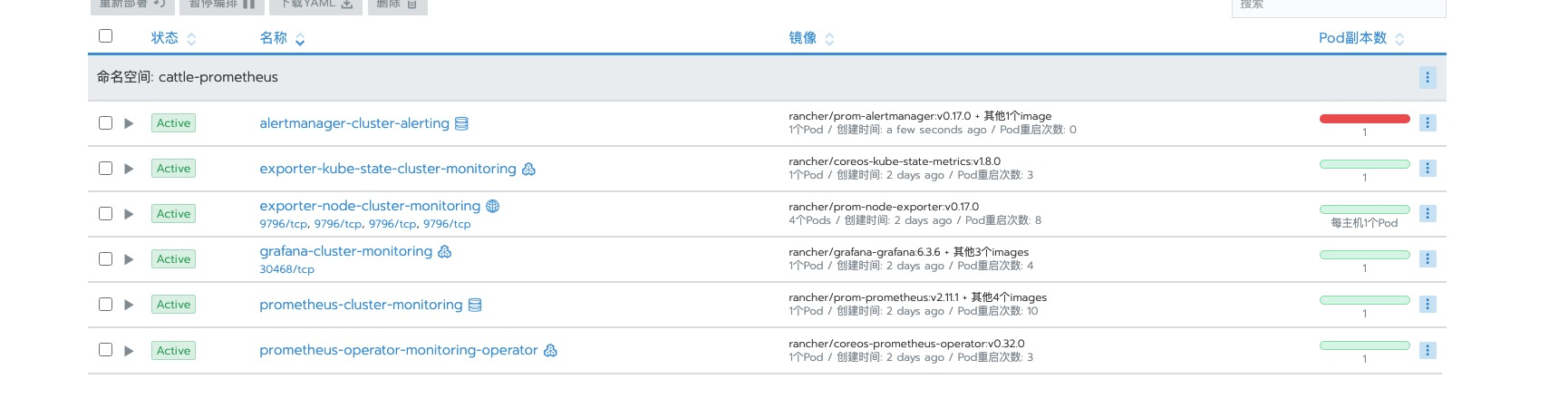
可以看到此时我们关联告警后,operator 后端为我们自动去创建了 alertmanger
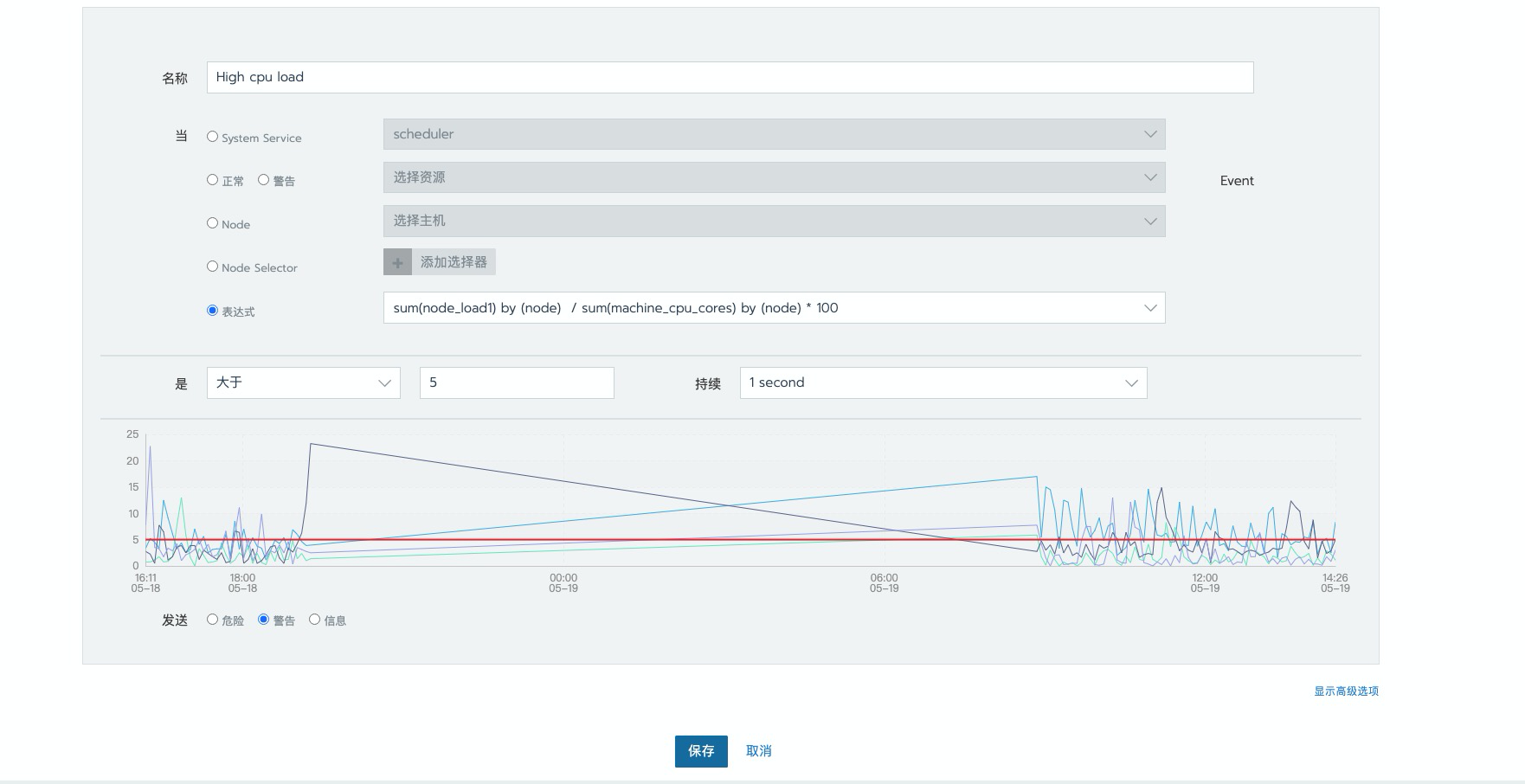
手动将阈值降低,触发告警
这里我们已 cpu 一分钟平均负载情况,作为示例,更改为 使用到
5%就触发告警,持续时间更改为 1s

等待一会后,已触发告警的发送了

这里告警出来后,alertmanger 这边还需要一段时间进行处理,趁这个时间,我们把 alertmanager 的 service 类型更改为前面 prometheus 一样的
NodePort类型。
1 2 3 4 5 6 7 8kubectl edit svc access-alertmanager -n cattle-prometheus ... app: alertmanager chart: alertmanager-0.0.1 release: cluster-alerting sessionAffinity: None type: NodePort ...
我们使用 对应的 NodePort 进行访问 alertmanger 的 dashboard
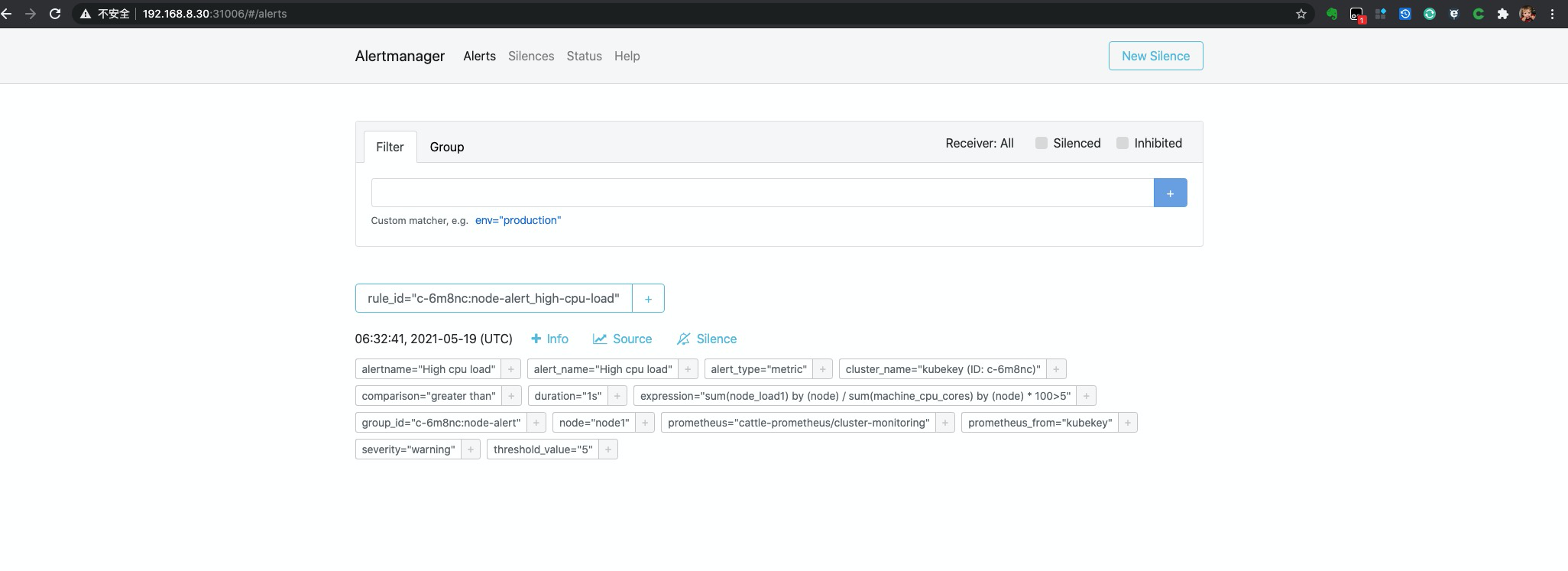
可以看到
alertmanger中也已有对应的告警通知,再次查看一下 dingtalk 这边也正常将通知出来了。
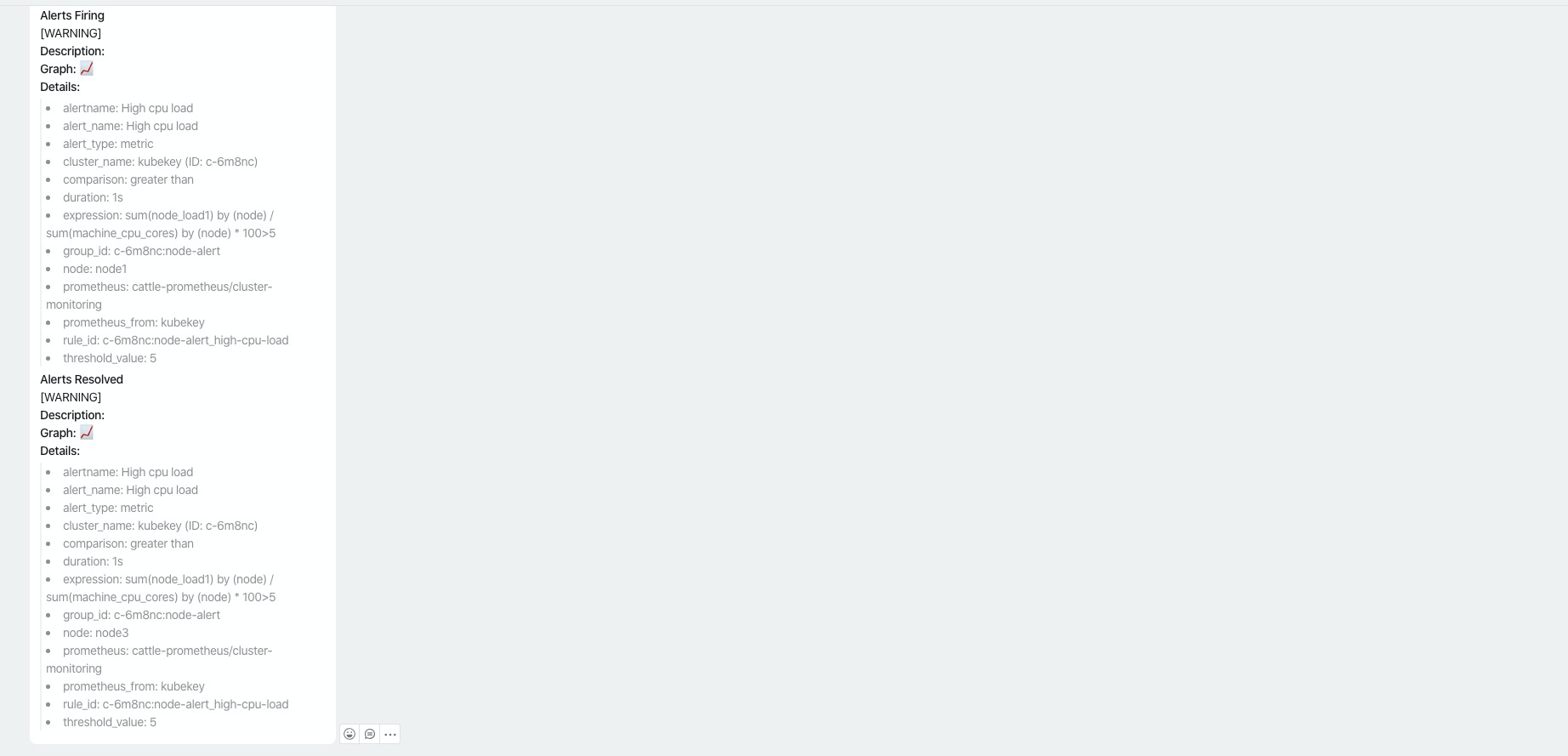
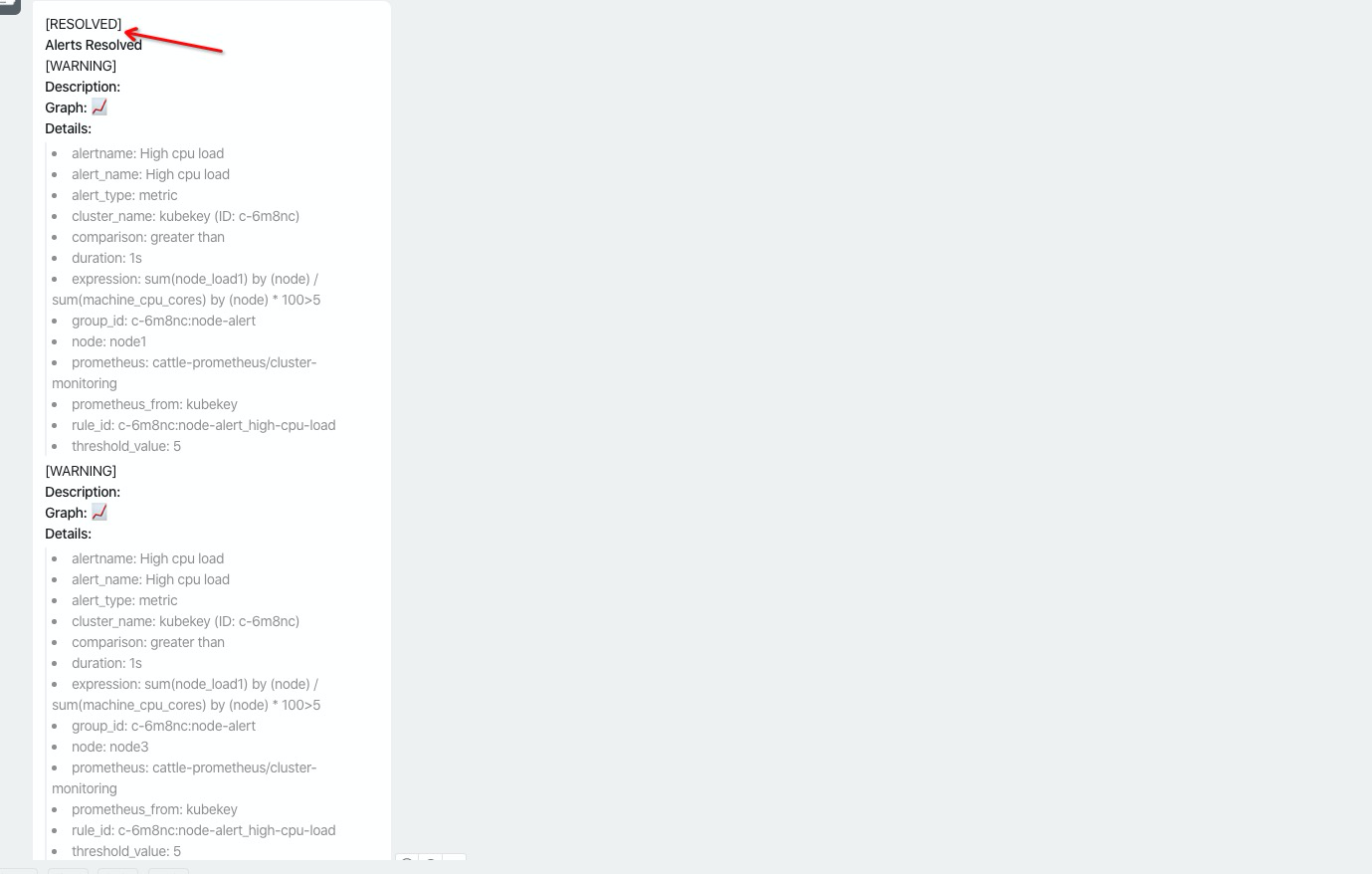
当我们把 阈值还原时,恢复通知也正常发送了出来
通知优化及阈值告警配置
阈值告警配置
alert rule请参考 此链接。
**在对应的告警组或新键的告警组中,参考上面链接中的 rule 配置添加即可 **

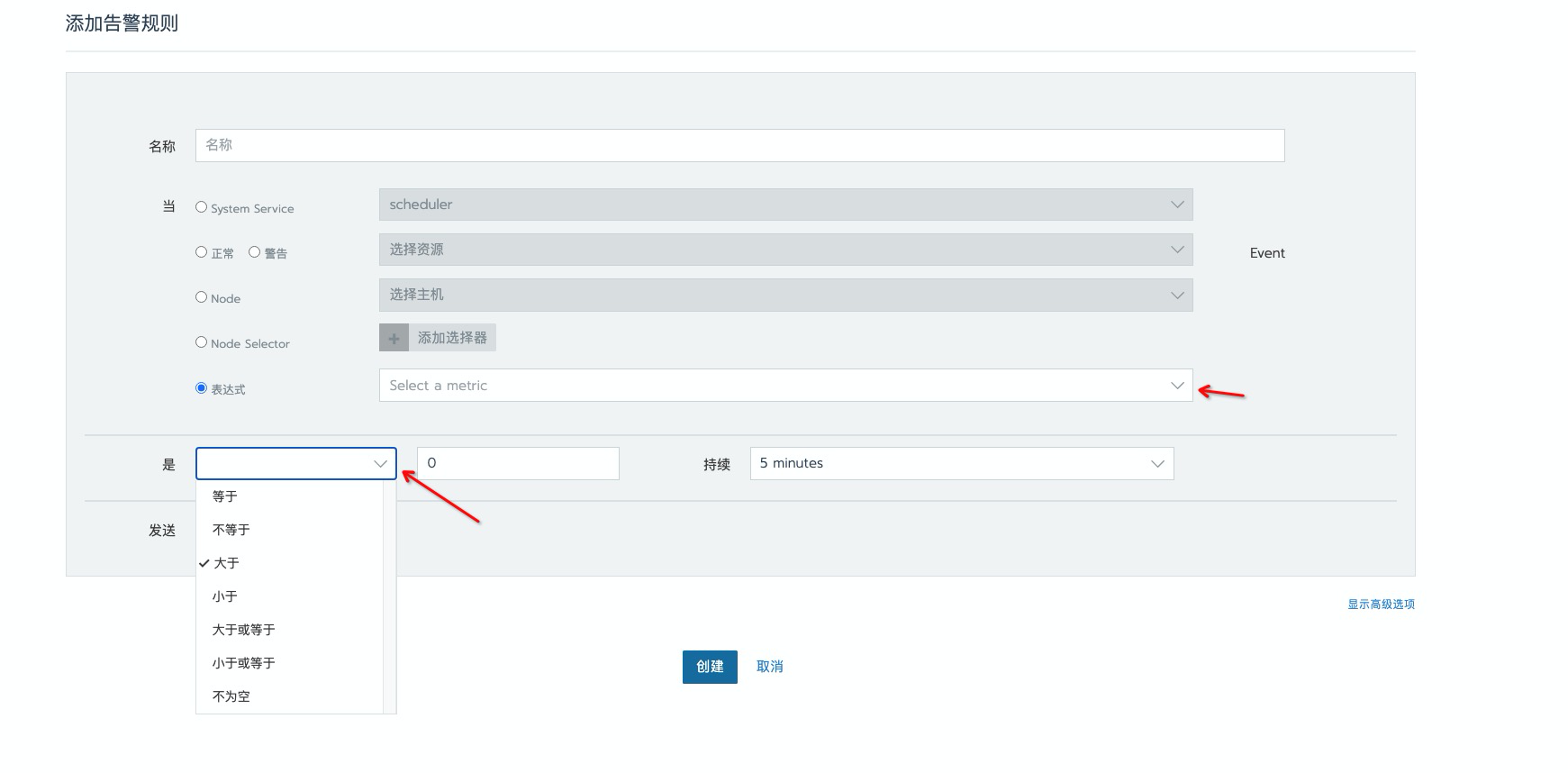
这里需要注意一下的就是,使用
表达式的这种方法相对更加灵活一些,还有就是需要注意一下rancher中也有逻辑判断符的,这里需要注意一下,不要重复添加了。
通知优化
-
图标链接更改优化
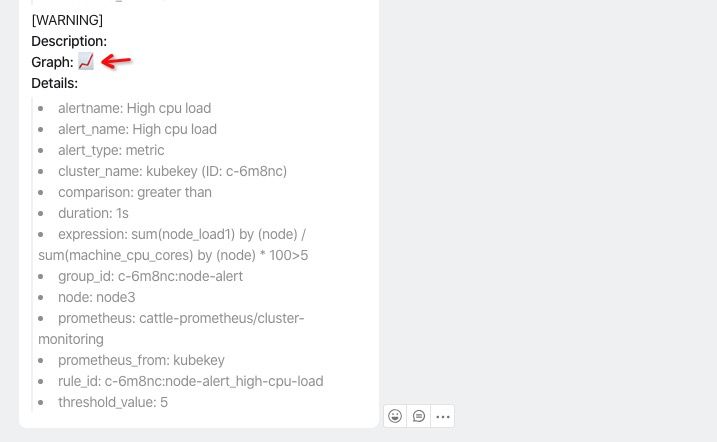
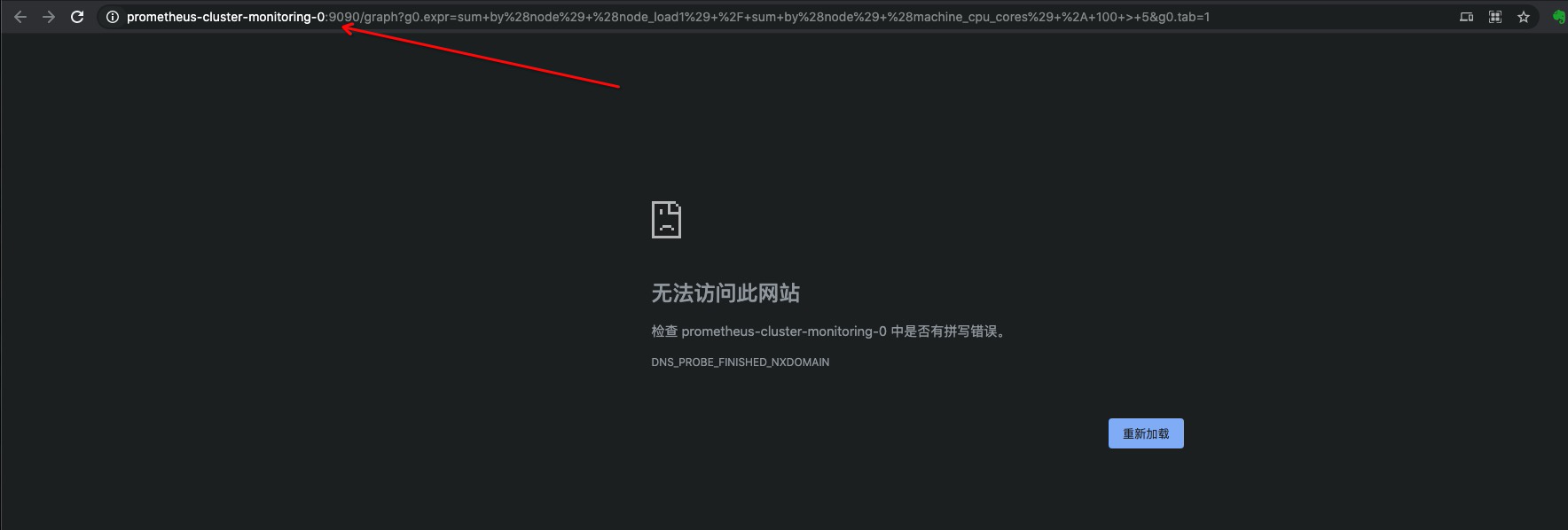
可以看到点击图标跳转的这个地址不对,对于故障的定位排除,点击就能跳转到正确的页面还是非常有之必要的。
-
修改
prometheus资源对象进行添加externalUrl配置即可1 2 3 4 5 6 7 8 9kubectl edit prometheus -n cattle-prometheus ... securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: cluster-monitoring externalUrl: http://192.168.8.30:32209 ...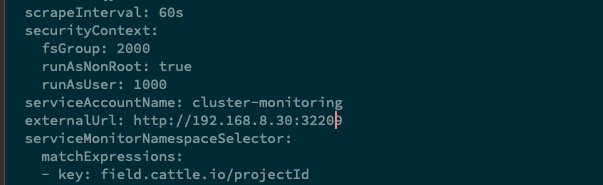
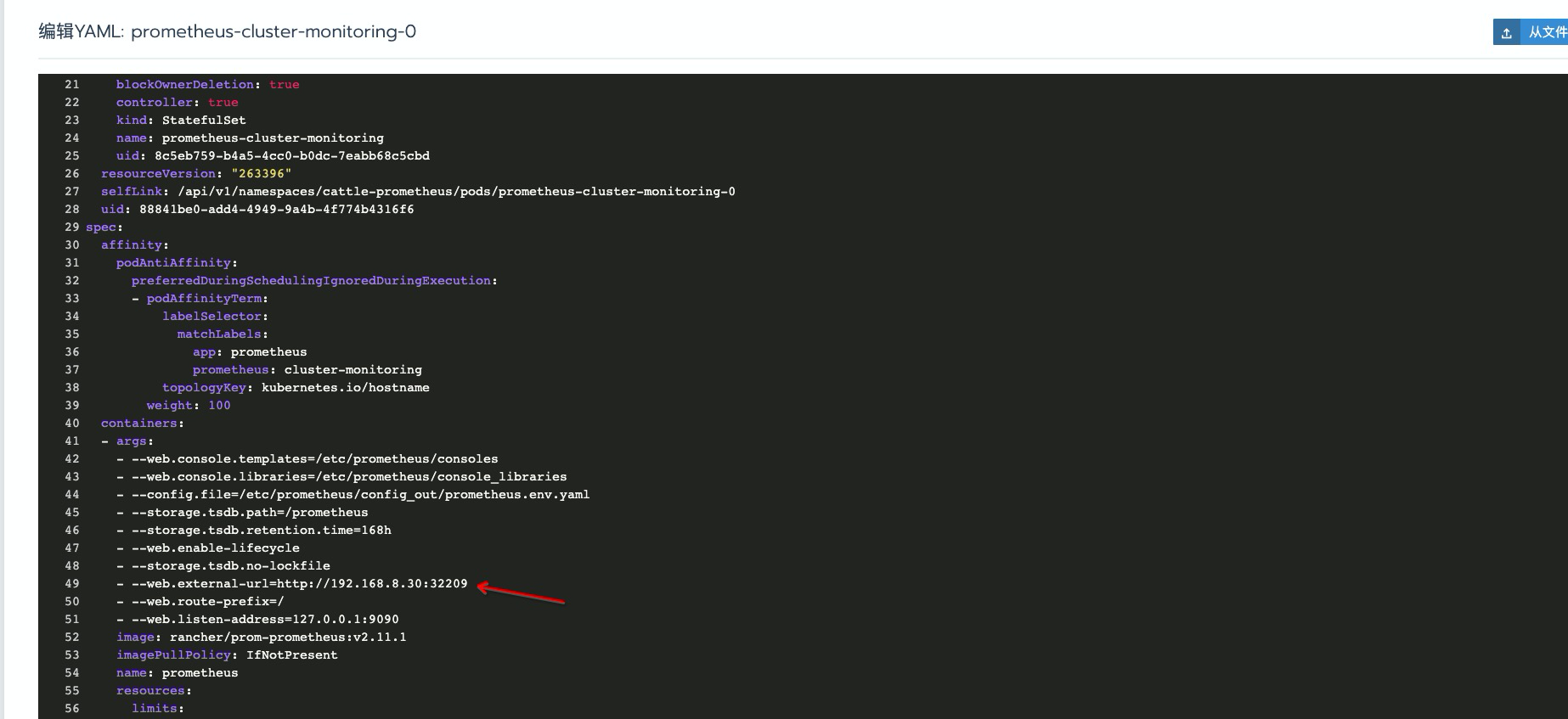
检查对应的
yaml可以看到 args 中 已添加了--web.external-url配置了,alertmanager的配置添加也是一样的,同样添加externalUrl字段即可。
To Do
…..