Coredns 出现间断性无法正常解析域名问题
文章目录
问题描述:
Kubernetes 节点中,有一台节点使用 coredns 进行解析某个域名时,出现间断性无法正常解析问题,而解析另外一个域名时不会出现解析问题。
再次重复一下问题重点:
且在集群中的某台节点中出现,且使用某个域名时出现
环境说明:
- 操作系统: CentOS Linux release 7.9.2009
- Kubernetes 集群: v1.17.4 (集群使用 rancher
自定义添加集群一键部署) - Dashboard: Rancher-v2.3.5
- Linux Kernel: 5.10.3-1.el7.elrepo.x86_64
- Coredns : Coredns:1.6.5 + Node-local-dns
工具说明
-
测试时使用的容器: praqma/network-multitool:latest
-
测试时使用的dns 测试工具 : coredns-tools.go
程序出自
Blog1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76package main import ( "context" "flag" "fmt" "net" "sync/atomic" "time" ) var host string var connections int var duration int64 var limit int64 var timeoutCount int64 func main() { // os.Args = append(os.Args, "-host", "www.baidu.com", "-c", "200", "-d", "30", "-l", "5000") flag.StringVar(&host, "host", "", "Resolve host") flag.IntVar(&connections, "c", 100, "Connections") flag.Int64Var(&duration, "d", 0, "Duration(s)") flag.Int64Var(&limit, "l", 0, "Limit(ms)") flag.Parse() var count int64 = 0 var errCount int64 = 0 pool := make(chan interface{}, connections) exit := make(chan bool) var ( min int64 = 0 max int64 = 0 sum int64 = 0 ) go func() { time.Sleep(time.Second * time.Duration(duration)) exit <- true }() endD: for { select { case pool <- nil: go func() { defer func() { <-pool }() resolver := &net.Resolver{} now := time.Now() _, err := resolver.LookupIPAddr(context.Background(), host) use := time.Since(now).Nanoseconds() / int64(time.Millisecond) if min == 0 || use < min { min = use } if use > max { max = use } sum += use if limit > 0 && use >= limit { timeoutCount++ } atomic.AddInt64(&count, 1) if err != nil { fmt.Println(err.Error()) atomic.AddInt64(&errCount, 1) } }() case <-exit: break endD } } fmt.Printf("request count:%d\nerror count:%d\n", count, errCount) fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount) }工具编译
1 2 3 4export CGO_ENABLED=0 export GOOS=linux export GOARCH=amd64 go build coredns-tools.go -
使用文件分享工具: nginx
配置文件如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15cat /usr/local/etc/nginx/nginx.conf # 且截取部分配置 server { listen 188; server_name _; charset utf-8; location / { root /Users/zun/Downloads; autoindex on; autoindex_exact_size off; autoindex_localtime on; } } nginx # 启动
问题表现
|
|
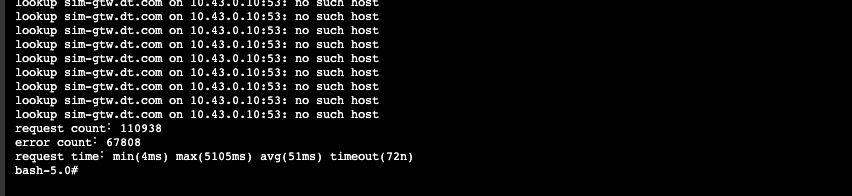
我们可以看到, 我们使用dns测试程序进行测试时,测试结果接近有
61%的解析失败率,而解析其他域名时解析是正常的

排查结果
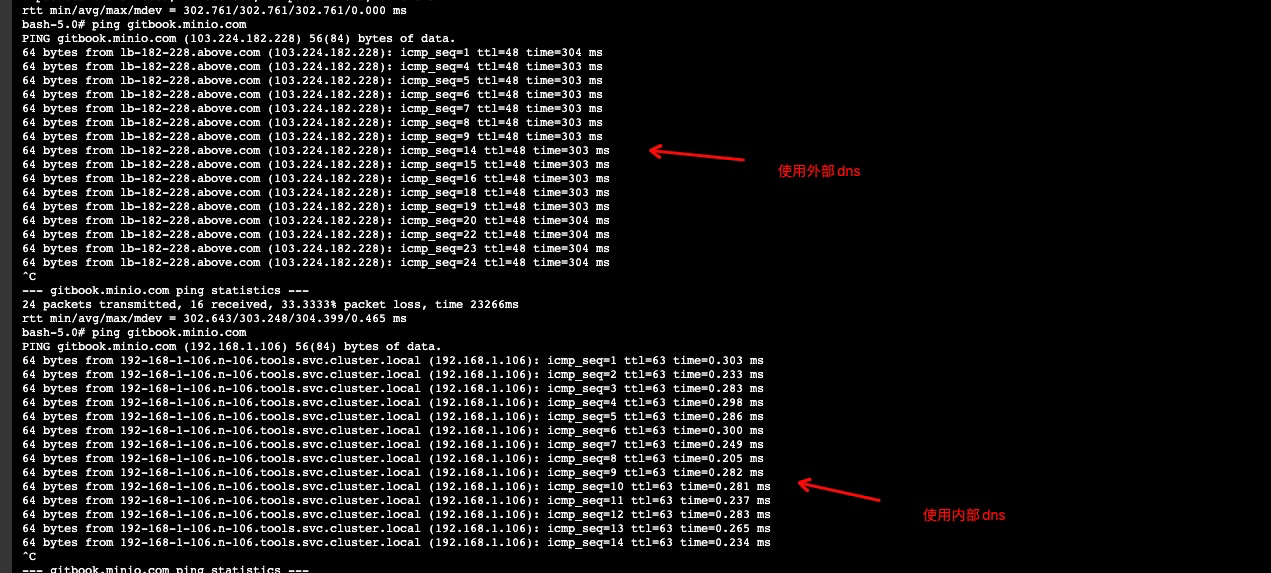
排查到结果与 Coredns 使用到的
上层DNS有关; 如下如截图所示中,使用同一个域名解析出来的地址, 一个是外网地址一个是内网地址,由此推断出解析域名时分别使用了不同dns server进行解析的。
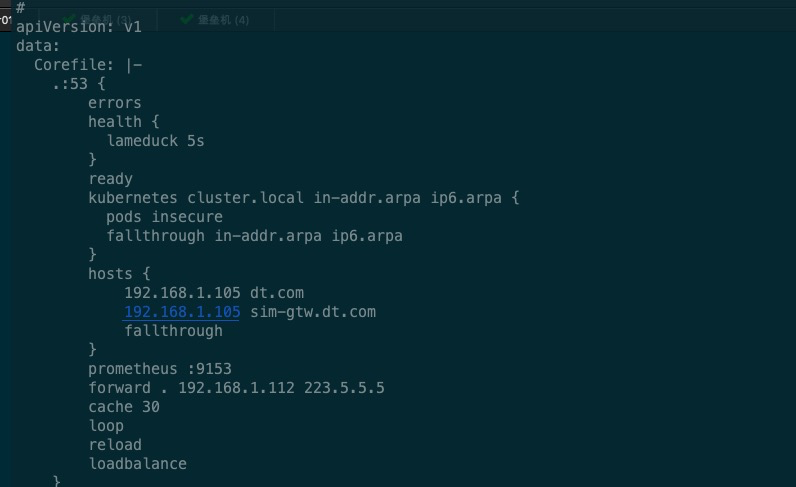
为了验证我们刚才的推断,我们在coredns 的 configmap 中开启 hosts 插件,并将相关域名写入其中。类似于主机中的 hosts文件,hosts文件优先于dns server,当拿到地址解析后客户端将不再继续请求上层dns server。
排查步骤如下:
步骤一:
|
|
步骤二:
修改完成后 等待 coredns pod 重新读取配置或手动删除 coredns 与之相关的
pod进行重载
|
|
修改后的结果展示:
重载配置完成后 我们再测试一下结果
|
|
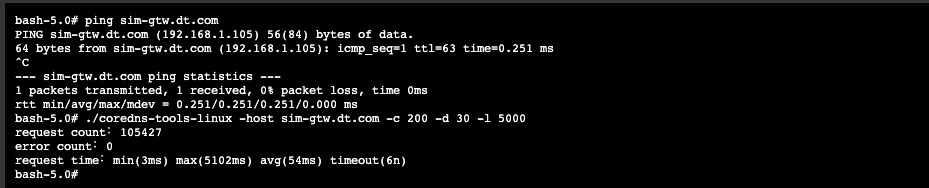
可以看到, 此时我们再进行测试时,域名解析已不再提示报错了。但是最大延迟显示还是显示有5s左右,这个和我们正在使用的kube-proxy策略有关,默认策略使用的是
iptables 模式,如后期优化可进行更改为性能更高的ipvs模式及部署 node-local-dns 服务来减少解析延迟,我这里无法更改 kubelet的启动参数中 dns的地址,貌似 node-local-dns 没有太多效果 。
解决问题
我们通过上面的测试验证了间断性域名解析失效,是由于上层dns造成;解决方法也非常简单,只需要更改 coredns 使其使用正确的上层dns即可。
更改 coredns 配置
同样我们需要更改一下 coredns 的 configmap 文件
|
|
更改后的 配置展示
|
|
适当的增减了 cache 时间与 ttl 时间
更改node-local-cahce 配置
|
|
更改后的配置展示:
|
|
更改完成后,继续等待 coredns 相关pod重载配置。 或手动重载。
1kubectl get pod -n kube-system |grep coredns|awk '{print $1}'|xargs -I {} kubectl delete pod {} --force -n kube-system
参考文档及博客:
部署 Nodelocaldns 解决 Coredns 域名解析延迟
总结:
原生的coredns功能方面还是存在某些不完善及兼容性的问题,不过我们可以使用第三方扩展来进行解决。目前coredns主要出现问题的地方在于: 内核的版本、网络插件兼容、5s超时问题,而五秒超时问题我们可以通过升级内核版本及部署 node-local-dns 应用在每个节点中增加缓存解决。